Dado que tenía que actualizar el post en el antiguo blog de Abstracta (que lo escribí en 2016), decidí pasarlo para acá. Este es el segundo paso del tutorial de Gatling. En este veremos específicamente el scripting en Scala, viendo qué hay dentro de un script, que tiene la particularidad de ser un texto plano en lenguaje Scala. Antes de pasar al script, veamos un par de cosas previas.
¿Por dónde comenzar con Scala?
Si bien nunca había visto nada en este lenguaje, me resultó fácil de leer y entender. Para conocer más del lenguaje se puede estudiar acá http://www.scala-lang.org/, pero desde mi punto de vista no hace falta, es suficiente con mirar la especificación y ejemplos que hay en el sitio de Gatling, porque al final no se trata solo del lenguaje en sí, sino de las funcionalidades que ofrece el framework, o sea, el DSL de Gatling (el lenguaje específico de la herramienta).
El script que se muestra en la documentación introductoria me resultó muy útil para entender mejor el funcionamiento, con lo cual te recomiendo que comiences por ahí. En este se explican los elementos claves del lenguaje y las funcionalidades brindadas, en particular es importante entender los conceptos de simulations, scenarios, feeders, loops y algunos más que iremos revisando.
Ambiente de desarrollo
Para trabajar con el texto siempre es muy útil tener un buen editor, que ayude a autocompletar, o al menos a colorear las cosas de acuerdo a la especificación del lenguaje. Aquí tenemos varias opciones. Al comienzo utilicé un editor de texto, pero me llevaba bastante trabajo darme cuenta de los errores de compilación que cometía y asiste muy poco al trabajo de escribir código. Como soy fiel usuario de Notepad++, comencé con este editor agregándole la definición del lenguaje que la descargué de aquí.
Luego probé un plugin de Eclipse para desarrollar en Scala, y creé un proyecto para el test al cual le tuve que agregar todas las bibliotecas que vienen con la herramienta.
En esta página mencionan algunos editores de Scala, y en particular comentan que hay plugins no solo para Eclipse, sino que también para IntelliJ IDEA y NetBeans.
Lo que terminé usando más fue el Visual Studio Code como cuento aquí.
El script recién grabado con el recorder de Gatling
El script recién grabado con algún ajuste menor, abierto con el editor de Notepad++ con el lenguaje definido se ve como muestra la imagen:
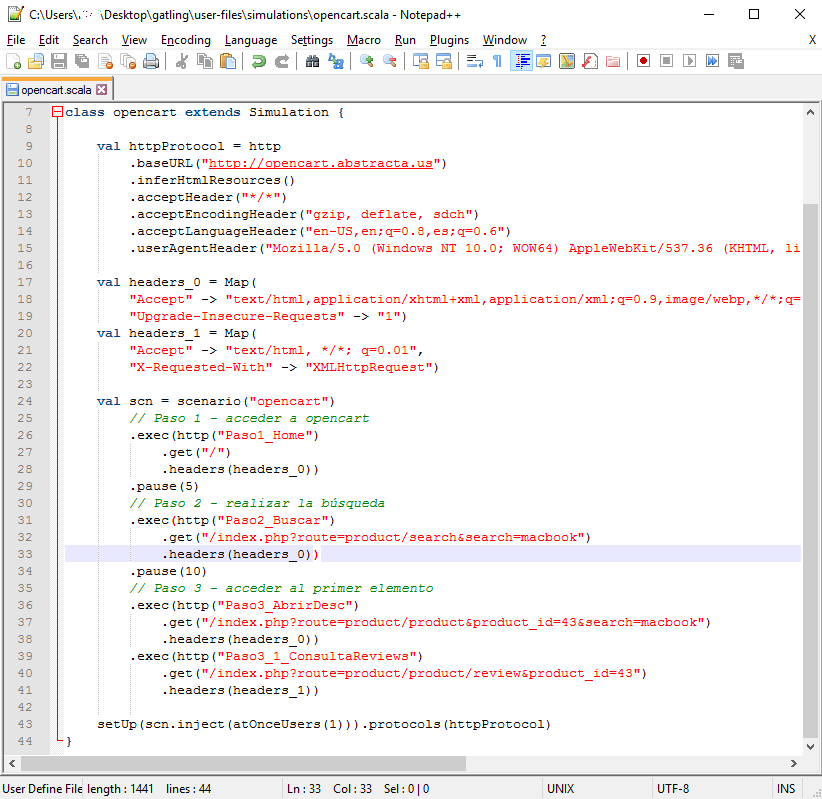
Por las dudas, el guión de prueba que me había definido era este:
- Acceder a opencart.abstracta.us.
- Introducir el texto “macbook” en el campo de búsqueda y presionar el botón de búsqueda.
- Acceder al primer producto que aparece en la lista para ver sus detalles.
Prestemos atención a un par de cosas del script:
- Como indiqué antes, es posible agregar comentarios durante la grabación que quedan en el código. Me parece muy importante aprovechar esto para que el script quede fácil de entender. Se puede ver un comentario en verde que dice “Paso 1 – acceder a opencart” por ejemplo.
- El Recorder graba los think-times. O sea, si hice una pausa entre una página y otra, agregará al script una espera explícita. Esto está muy bien, ya que para simular un usuario real no queremos que ejecute un request enseguida del otro, pero recomiendo revisar el script por si quedó alguna pausa muy exagerada o no muy de acuerdo al comportamiento normal de los usuarios.
- El script quedó bien corto y simple gracias al uso de “infer html resources” tal como lo expliqué en el post anterior. Si no fuese por esto aparecería un request más por cada imagen, archivo CSS, JavaScript, etc., que se utiliza en cada página.
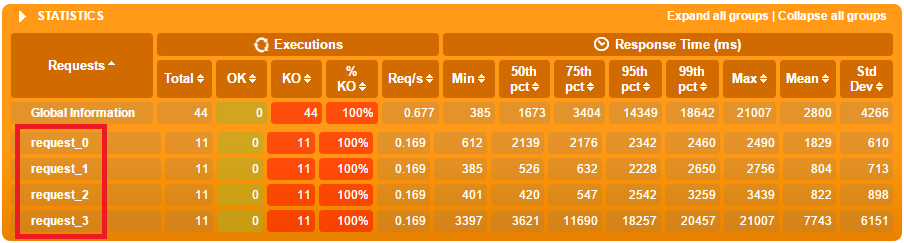
- Parte de las modificaciones que le hice al script grabado fue modificar las líneas “.exec(http(“request_0”)”, donde “request_0” identifica al paso. Conviene renombrar los “request_X” a algo más legible ya que estos forman parte de los informes. Se puede ver esto reflejado en la siguiente imagen. El reporte podría ser mucho más legible si en lugar de “request_0” dijera “Paso1_Home” o lo que corresponda. Esto lo veremos en más detalle luego, al hablar de reportes.
Organización de un script: apostando a la mantenibilidad
Si bien todos sabemos que los scripts a nivel de protocolo son casi imposibles de mantener y a cada poco tenemos que rehacerlos casi de cero, Gatling presenta un enfoque bien interesante que quizá permita apuntar a mantener los scripts y no tirarlos a la basura luego de la ejecución de un ciclo de pruebas.
Además, casi que el slogan de Gatling es que debemos considerar el código de pruebas de performance como código de producción. Esto es algo que con herramientas como JMeter se vuelve muy difícil de realizar.
La herramienta maneja un concepto muy interesante, similar a Page Object para Selenium o cualquier enfoque de testing funcional automatizado. Aquí está muy bien explicado. En la siguiente imagen se pueden ver los cambios realizados para seguir este patrón de diseño:
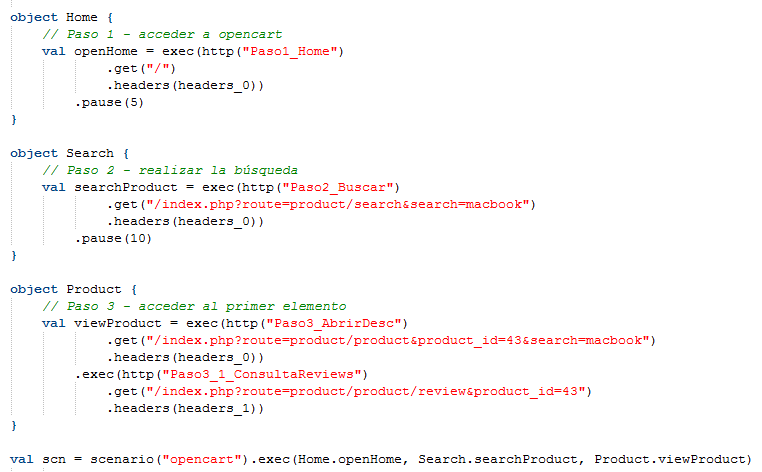
De esta forma la definición del escenario queda más legible y más fácil de modificar. Por otra parte, si algo cambiase, al tener esta modularización podríamos ajustar solo la página que cambió, y de esa forma todos nuestros scripts y escenarios quedarían actualizados con la menor cantidad de cambios posible. El cambio del código del script no afecta para nada en la forma en que se muestran los resultados, es solo un aspecto de calidad de código y facilidad de mantenimiento.
Una buena estrategia para esto es tener archivos separados por cada una de las páginas que están consideradas en las pruebas, en las cuales se definan esos objetos. Cada objeto tendrá las distintas acciones que se pueden desencadenar desde esas páginas. De este modo podría ser bien simple localizar los métodos afectados al estar coordinados con el equipo de desarrollo. Incluso más: cada historia podría tener dentro de su DoD (definition of done) que se haga un simple test, el cual podría ser luego incluido en una prueba mayor.
Configuración de Escenarios de Carga
Si bien esto es de lo último que uno configura en un script, prefiero verlo ahora ya que seguiremos ejemplificando con ejecuciones, entonces es necesario tener claro cómo se entiende la definición de lo que se ejecuta, o sea, la cantidad de usuarios concurrentes, durante cuánto tiempo, en qué forma ingresan los usuarios, etc.
Se pueden definir los escenarios como una secuencia de pasos, y en esos pasos definir los requests. Se pueden definir entonces diferentes escenarios de esa forma:
val users = scenario("Users").exec(Search.search, Browse.browse)
val admins = scenario("Admins").exec(Search.search, Browse.browse, Edit.edit)
Estos escenarios se pueden luego ejecutar con determinado ramp-up (para que no ingresen el total de usuarios de una, sino que accedan progresivamente durante cierto tiempo).
setUp( users.inject(rampUsers(10) during (10 seconds)), admins.inject(rampUsers(2) during (10seconds)) ).protocols(httpConf)
Se puede definir el escenario en transacciones por segundo:
scn.inject(rampUsers(500) during (10 minutes)).throttle(reachRps(100) in (10 seconds), holdFor(10 minutes))
Veamos ahora más detalles relacionados a cómo armar adecuadamente la simulación de un usuario virtual, o sea, preparar un script que simule las acciones que realizaría un usuario real de la manera más fiel posible.
Validaciones / Assertions
Uno de los aspectos fundamentales de todo caso de prueba es que se pueda validar la respuesta, y evitar falsos negativos, esto es, que quizá estamos obteniendo tiempos excelentes y es porque la aplicación está respondiendo “bad request” en lugar de procesar el pedido que estamos realizando. Es necesario tener mecanismos que nos permitan verificar las respuestas, no al mismo detalle que lo haríamos en una prueba automatizada funcional, pero al menos buscar textos en el body de la respuesta o en los headers. Para ver cómo hacer buenas validaciones recomiendo este post de Leticia Almeida, que si bien está enfocado en JMeter, aplica a cualquier herramienta para pruebas de performance.
Para las validaciones Gatling provee del elemento “check”. La documentación al respecto está aquí. Algunos ejemplos aplicados al script que estuve armando:

En este ejemplo se verifica que el código de respuesta del paso 1 (pantalla inicial) sea 200, que no aparezca la palabra “Error” y que aparezca algún link (los ejemplos fueron un poco arbitrarios, pero con la finalidad de mostrar distintos aspectos que se pueden validar).
Algo interesante a saber, si no se agregan validaciones de forma explícita, se realiza una validación automática que verifica que el código de respuesta es 2XX o 304 (no entendía por qué un 304 estaría bien, y no lo estaría un 302 o 303, pero revisando el RFC de HTTP vi que el 304 es específicamente para los elementos que no han sido modificados, que se hace una petición condicional, lo cual entiendo que es especialmente útil para recursos como archivos CSS, JavaScript o imágenes).
Otro aspecto importante, si un chequeo falla en un request, entonces no se realizan los pedidos secundarios, o sea, no se piden los recursos embebidos en esa página, ya que directamente se corta el script.
Las validaciones de la imagen están aplicadas a un solo request. Un concepto bien interesante que maneja Gatling son las validaciones globales (documentación completa aquí).
assertThat( global.responseTime.max.lessThan(5550) global.successfulRequest.percent.greaterThan(95) ) setUp(...).assertions( global.responseTime.max.lessThan(50), global.successfulRequests.percent.greaterThan(95) )
De esta forma estaríamos definiendo criterios de aceptación globales a la prueba. También se pueden definir distintos criterios de esta forma:
setUp(…).assertions( details(requestName).requestsPerSec.greaterThan(60), details(requestName).responseTime.percentile3.lessThan(5s), details(requestName).failedRequests.percent.lessThan(1), details(requestName).failedRequests.percent.lessThan(1) )
Control de fallas
Asociado a las validaciones tenemos al control de fallas y excepciones, o sea, controlar qué hacer cuando se encuentra un error. Por ejemplo, se puede reintentar varias veces, cortar la ejecución de un bloque entero, etc.
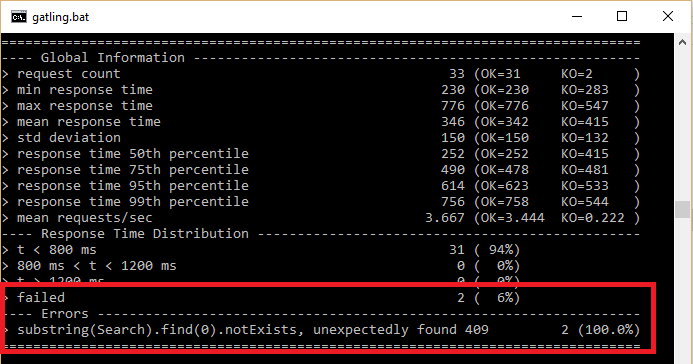
Podemos definir que cierto bloque de código se intente varias veces en caso que haya una falla con tryMax. Para ejemplificar cómo funciona esto, agregamos una validación que falle a uno de los pasos, así luego al ejecutar podemos observar que se haya reintentado. Esto se logra como muestra la siguiente figura:

Y en el resultado de la ejecución podemos ver que como el string “Search” se encuentra en la respuesta, con lo cual el script falla (observar el “notExists”), entonces intentó ejecutar dos veces. Esto se puede observar en el recuadro rojo:
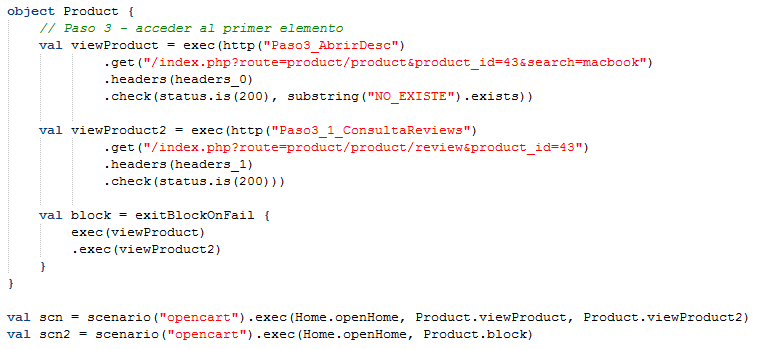
Por otra parte, podríamos definir que, si hay un fallo en algún paso, directamente se corte toda la ejecución de un bloque. Para esto modificamos el script como se muestra a continuación, tenemos dos sub-pasos para el paso 3 con una validación como para que falle a propósito, y un bloque que los combina con el método exitBlockOnFail.
Definimos dos escenarios, uno para que ejecute la página de inicio, los dos pasos por separado, y luego un escenario que ejecuta la página de inicio y el bloque. Así veremos la diferencia que plantea usar el bloque.
El resultado de ejecución del escenario “scn” muestra que se ejecutan los 3 pasos:

Sin embargo, al ejecutar “scn2” que considera ejecutar el bloque, ejecutó los primeros dos pasos, y el tercero no, ya que al fallar algo del bloque lo cortó:

Al margen, pero de todos modos importante, es que en este ejemplo comenté la línea “.inferHtmlResources()”, así de esa forma el debug se hace más rápido, ya que no se invocan los pedidos secundarios. Esto es ideal para toda la etapa de automatización, pero no hay que olvidarse de descomentarlo al finalizar, antes de ejecutar las pruebas.
Manejo de cookies, cache y otros aspectos de HTTP
Tal como lo cuenta la documentación, Gatling no es un browser, o sea, no ejecuta JavaScript ni aplica estilos CSS, trabaja a nivel de protocolo. Algo fundamental en toda herramienta que trabaja a nivel de HTTP es el manejo de cookies. En el caso de Gatling las cookies se manejan en forma transparente y automática, tal como lo haría el browser. Nunca entendí por qué en JMeter es necesario agregar un elemento específico para eso, cuando en todos los casos vamos a necesitar que se haga una gestión adecuada de cookies.
De todos modos, para los casos en que haga falta agregar cookies de forma explícita, se cuenta con algunas funcionalidades para este fin que están documentadas aquí.
Por otra parte, otro aspecto que me gusta muchísimo de Gatling, es que maneja el caché tal como lo hace un browser, considerando los headers que indican el tiempo de expiración y última modificación. Esto se puede deshabilitar, pero por defecto lo hace. Más información aquí.
En esta misma página se puede ver que hay muchos aspectos más de HTTP que son tenidos en cuenta, y otro fundamental es la autenticación, especialmente necesario para aquellos sitios que lo realizan por LDAP o Active Directory.
También se codifican los requests en forma automática. Imaginemos que tenemos un request parametrizado donde se le pasa el nombre del producto, ¿qué pasa si buscamos un producto que tiene un espacio o algún carácter no permitido en una URL? La respuesta es que se deben encodear. No nos tenemos que preocupar por esto ya que Gatling lo hace automáticamente.
Control de flujo
Muchas veces resulta necesario manejar el flujo de control de ejecución de un script, ya sea agregando condicionales if-then-else como agregando bucles tipo loop. Todas estas cosas están contempladas, copio aquí los dos ejemplos que considero más básicos y necesarios para esto, tomados de la documentación.
object Browse {
val browse = repeat(5, "n") { // 1
exec(http("Page ${n}")
.get("/computers?p=${n}")) // 2
.pause(1)
}
}
doIf("${myBoolean}") {
// executed if the session value stored
// in "myBoolean" is true
exec(http("...").get("..."))
}
Parametrización
Si quiero simular 500 usuarios accediendo al sitio de e-commerce, cada uno buscando un producto y mirándolo, no puedo hacerlo siempre con el mismo producto, ya que esto ocasionaría ciertos comportamientos que no simularían fielmente la realidad:
- El servidor tendría los cachés a favor, tanto los que están a nivel web como en la base de datos.
- Se podrían generar bloqueos que no son reales, todos los usuarios queriendo acceder al mismo registro (a menos que el dueño del sitio de e-commerce solo venda aspirinas).
Por este motivo es que siempre es necesario analizar qué datos hay que variar para que la prueba sea real. Una vez definidos los datos a variar, es necesario parametrizar el script. En particular Gatling usa el concepto de “Feeders” para parametrizar los tests.
Hay muchos tipos de feeders, para consumir datos de diversas fuentes (bases de datos, archivos, etc.), pero el más común considero que es el archivo CSV (archivo de texto plano separado por comas).Para nuestro ejemplo de buscar productos en OpenCart, podríamos definir un archivo llamado “products.csv” en la carpeta “data” dentro del directorio de Gatling, con el siguiente contenido:
product Macbook Desktop Camera Tablets
La primera fila se considera el nombre de la variable (es muy útil cuando tenemos varias columnas, separadas por coma), y el resto de las filas son los datos que se usarán para esa variable.
En el código debemos definir de esta manera:
val feeder = csv("products.csv").random
En este caso estamos indicando que se tomen los datos en orden aleatorio, pero hay diferentes formas de tomarlos (secuencial, diferentes órdenes, etc.). Luego las variables se usan similar a como se usan en JMeter, en todos los lugares donde decía “macbook” sustituimos por “${product}”.

Así logramos que en cada ejecución se utilice un valor diferente en esa variable, lo que equivale a que cada usuario que simulamos hará una búsqueda diferente.
Es importante no olvidarse de agregar la invocación a “feed” para que se carguen las variables:
val scn3 = scenario("opencart").feed(feeder).exec(Search.searchProduct)
Más información sobre feeders acá.
Correlación de variables
Para trabajar con sitios dinámicos es fundamental manejar variables de forma correlacionada, esto es, tomar datos de las respuestas que luego son enviados en los siguientes requests. Esto es algo que por lo general es muy transparente para el usuario pues lo resuelve el browser sin que nos demos cuenta.
Siguiendo el ejemplo, cuando buscamos un producto y hacemos clic en el primero, podemos ver que en la URL de la invocación del paso 3 hay un parámetro que es product_id y se envió con el valor 43, el cual corresponde a la Macbook que aparecía como primer resultado de búsqueda. Como parametrizamos la búsqueda, cada usuario obtendrá distintos resultados, y lo que corresponde es que en el paso tres se intente visualizar el primer producto que aparece en la respuesta de la búsqueda.
Es necesario entonces poder obtener el product_id correspondiente, para lo cual utilizaremos nuevamente los “check” pero esta vez con una funcionalidad extra que nos permite almacenar lo que obtenemos de una expresión regular en una variable. Se puede observar en la siguiente figura el código subrayado en rojo:
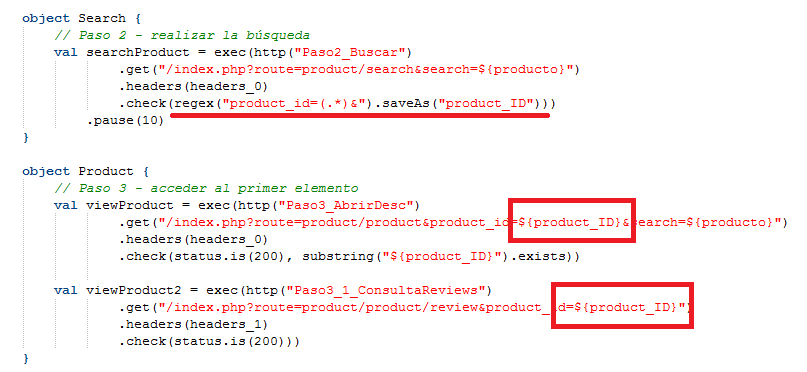
Ahí se puede ver que se extrae el identificador del producto buscádolo en la respuesta con una expresión regular. Esto lo carga en una variable que es utilizada luego (en los recuadros rojos).
Podés encontrar más información de este mecanismo aquí.
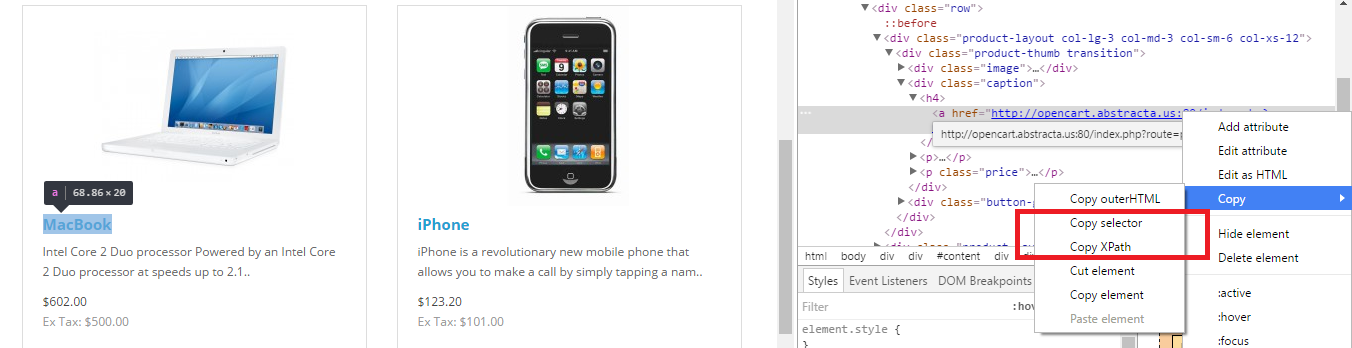
Lo novedoso es que se pueden buscar valores con distintos mecanismos, no solo por expresiones regulares, también se pueden usar CSS Selectors y XPaths tal como en Selenium. Para esto hay diversas herramientas que nos ayudan a encontrar el XPath o CSS selector para localizar elementos en una página; incluso el “inspeccionar elemento” en el browser cuenta con la posibilidad de extraerlos tal como muestra la siguiente imagen:
Cierre
Con esto vimos lo que me parece más importante como para comenzar a preparar scripts en Gatling. En el próximo post nos centraremos en la ejecución y reportes de la herramienta que es uno de los aspectos destacables.