En este artículo les comparto algo escrito por Marcos Pérez de Abstracta, contando su experiencia al probar una API de forma “manual” utilizando la heurística POISED explicada en el curso “Exploring Service APIs Through Test Automation” de Test Automation University por Amber Race.
Si bien el curso está enfocado en automatización de pruebas a nivel de API, en mi caso, resultó de gran utilidad para probar una API con foco en su funcionalidad, de manera “manual”/exploratoria, por lo que recomiendo realizar el curso dado que además de explicar en detalle la heurística propuesta (uno de los objetivos de este post) se explican conceptos sobre API testing, se mencionan herramientas para pruebas, entre otras cosas.
Heurística POISED para API testing
En mi caso utilizaba la heurística POISED como checklist al momento de diseñar los casos de prueba sobre determinada API. Se tornaba realmente útil cuando surgía la pregunta “¿estoy cubriendo todos los aspectos importantes de la API?”
Siguiendo dicha heurística se cubren varios aspectos interesantes a probar como lo son:
- Parameters (Parámetros): considerar todos los parámetros pasados a la API.
- Output (Salidas): validar las salidas adecuadas para parámetros válidos e inválidos.
- Interoperability (Interoperabilidad): verificar la coherencia con otras API.
- Security (Seguridad): verificar el mantenimiento del acceso y la autorización para las llamadas a la API.
- Exceptions (Excepciones): verificar que se informen los errores de forma clara y precisa.
- Data (Datos): verificar que se manejen las estructuras de datos y los datos reales correctamente y en el tiempo adecuado.
Operación para ejemplificar
Para explicar punto a punto la heurística y mostrar algunos ejemplos vamos a considerar una operación POST simple sobre determinado endpoint que se encargaría de crear una persona o usuario en la base de datos, a partir de los valores enviados en el body del mensaje con datos básicos de una persona o usuario de un sistema:
{
“firstname” : “XXX”, (alfanumérico de largo 10)
“lastname” : “YYY”, (alfanumérico de largo 10)
“age” : ZZ (solo números enteros de largo 2)
}
1- Parámetros
A continuación un ejemplo de una invocación incluyendo los valores a enviar en los parámetros:
{
“firstname” : “Juan”,
“lastname” : “Pérez”,
“age” : 30
}
Cuando hablamos de parámetros válidos o inválidos nos referimos en este caso a los parámetros “firstname”, “lastname” y “age” utilizando valores válidos (los valores en el ejemplo) o valores inválidos como podrían llegar a ser (dependiendo del comportamiento de cada API) valores vacíos, caracteres especiales, espacios en blanco, valores “null”, no enviar determinado parámetro, tipos de datos no soportados, entre otros. Aquí un ejemplo:
{
“firstname” : “ ”,
“lastname” : “lastname”,
“age” : “string”
}
Es importante considerar el criterio de “no solapamiento de errores”, tal como Federico lo explica en su libro. También aplicar las técnicas típicas de caja negra, como clases de equivalencia y valores límite, y técnicas de combinación de datos como pairwise.
2- Salidas
El siguiente aspecto a considerar son las salidas de una operación, esto incluye el status o códigos de respuesta http, el body o cuerpo de salida, headers devueltos, etc.
Siguiendo con el ejemplo planteado, la idea es que dependiendo de si la persona es mayor de edad (mayor o igual a 18) o menor (menor a 18) se obtengan distintas respuestas en la operación. En este caso estaríamos enviando datos de una persona mayor de edad:
{
“firstname” : “Juan”,
“lastname” : “Pérez”,
“age” : 30
}
Supongamos que la respuesta fue la siguiente:
Status: 200 OK Body: “La persona creada es mayor de edad.”
Mientras que si lo que enviamos son datos de una persona menor de edad por ejemplo:
{
“firstname” : “Juan”,
“lastname” : “Pérez”,
“age” : 15
}
Podriamos obtener una salida distinta a la anterior:
Status: 200 OK Body: “La persona creada es menor de edad.”
Códigos de estatus http más comunes:
- 200: OK
- 3xx: redirección
- 301: Permanent Redirect
- 302: Temporary Redirect
- 4xx: error del lado del usuario (del que invoca)
- 403: Forbidden
- 404: Not Found
- 5xx: error del lado del servidor
- 500: Internal Server Error
- 503: Service Unavailable
Además de pensar en los códigos de respuesta de salida, es posible aplicar las técnicas de clases de equivalencia y valores límite sobre las variables de salida (esto complementa el punto anterior donde dijimos de aplicarla sobre las variables de entrada).
3- Interoperabilidad
El tercer aspecto a considerar según la heurística POISED es el de interoperabilidad.
Según Wikipedia, la IEEE define interoperabilidad como la habilidad de dos o más sistemas o componentes para intercambiar información y utilizar la información intercambiada.
En este caso lo que se intenta probar es que la interacción entre distintas operaciones o APIs funcione como se espera.
En el ejemplo de crear una persona o usuario se tenía el parámetro “age”, si dicho parámetro en la operación de crear (POST) solo acepta enteros de largo 2 (por ejemplo “20”) se esperaría que al consultar el usuario con otra API, el parámetro “age” también admita solo números enteros de largo 2, en caso contrario, si admite un string (por ejemplo “veinte”) estaríamos en presencia de un potencial problema de interoperabilidad. Es importante que si detectamos estos tipos de comportamientos comuniquemos al equipo y consultemos si el mismo es el deseado y en caso caso afirmativo asegurar que la API esté bien documentada, especificando los tipos de datos de cada parámetro o campo y evitarle problemas de interoperabilidad a quienes quieran hacer uso de nuestra API.
4- Seguridad
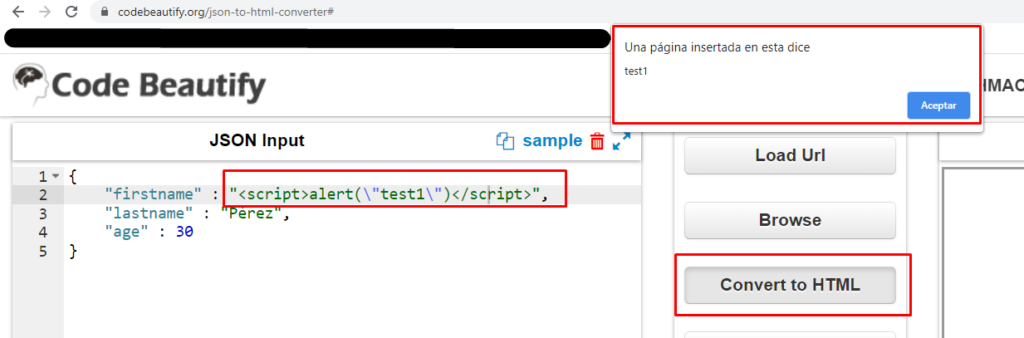
Otro aspecto a considerar según la heurística es la seguridad de nuestra operación, lo cual implica una enormidad de desafíos. Por ejemplo, esto puede incluir autenticación o aspectos de seguridad en los parámetros, como por ejemplo verificar el comportamiento enviando scripts como valores:
{
"firstname" : "<script>alert(\"test1\")</script>",
“lastname” : “Pérez”,
“age” : 30
}
Si al ejecutar la consulta de este registro obtenemos ese valor, podríamos tener una posible vulnerabilidad. Una forma de verlo es si convertimos la respuesta html, se puede observar que se ejecuta el script ingresado dentro del parámetro “firstname” (esto daría lugar a ciertas vulnerabilidades):
En mi opinión es importante tener un set de pruebas básicas sobre seguridad en los datos más allá de tener o no pruebas específicas sobre la seguridad de la API realizadas por especialistas en ese rubro.
5- Excepciones
El siguiente aspecto según la heurística es sobre el manejo de los errores por parte de la API, lo cual incluye tanto el código de respuesta http como un mensaje informando el error si corresponde. Continuando con el ejemplo planteado y suponiendo que el campo “firstname” es obligatorio, al enviar el siguiente cuerpo (sin enviar el parámetro “firstname”):
{
“lastname” : “Pérez”,
“age” : 30
}
Se esperaría que devuelva un código de respuesta “400 Bad Request” con un mensaje informando el error, por ejemplo: “Error, No se envió campo ‘firstname’”. Si por el contrario observamos que devuelve un código de respuesta incorrecto, como podría llegar a ser “500 Internal Server Error” (lo que indicaría que el servidor no fue capaz de procesar la invocación y se produjo un error no controlado), o peor, “200 OK”, o un mensaje de error incorrecto (por ejemplo un mensaje vacío) estaríamos frente a un error de manejo de errores por parte de la API.
6- Datos
Por último pero no menos importante, se deberían probar aspectos relacionados a los datos, entre ellos la persistencia para el caso que corresponda. Siguiendo con el ejemplo anterior si creamos una persona o usuario con los siguientes datos:
{
“firstname” : “Juan”,
“lastname” : “Pérez”,
“age” : 30
}
Si existiese una operación de consulta de personas o usuarios dentro de la API (sería una operación GET) deberíamos verificar que se devuelvan los datos tal cual los ingresamos, en este caso los campos “firstname” con el valor “Juan”, “lastname” con valor “Pérez” y por último “age” con el valor “30”. Aquí también podemos aplicar nuestras típicas técnicas de testing para determinar datos de prueba interesantes, como por ejemplo clases de equivalencia y combinación por pares, o ya que estamos hablando de bases de datos, aplicaría usar la técnica CRUD.
Conclusión
Dada la experiencia obtenida tras el uso de la heurística tanto para la creación de casos de pruebas como la ejecución de las mismas, puedo decir que me resultó muy útil, incluso para la ejecución de pruebas exploratorias llegando a verificar varios puntos en conjunto.
La heurística podría llegar a servir de alguna manera para estandarizar dentro de un equipo de varios testers la forma de probar una API, manteniendo una estructura y enfoque. Da un modelo de referencia para tener en cuenta al pensar la cobertura que nos interesa alcanzar al probar una API.
Existen otras formas muy interesantes de probar una API (incluso otras heurísticas, por ejemplo recomiendo leer sobre la heurística VADER). En definitiva, hay que lograr encontrar la forma de probar que sea más adecuada para tu equipo de trabajo o contexto de proyecto.


Qué evolución. Ahora aclarás que el artículo lo escribió otro, no como los demás donde te ubicás como “coautor” sin contribuir en nada.
Darío, qué tal?
Ayudame a entender porfa, si ves alguno que sepas que está mal indicada mi co-autoría, dámelo a saber así lo ajusto. Suelo dedicarle bastante tiempo y acompañamiento a la gente con la que generamos contenidos, y me interesa seguir haciéndolo. Es muy importante que cada uno reciba su correspondiente atribución.
Saludos