En este post vamos a ver cómo distribuir carga con Gatling al ejecutar pruebas de performance (si no conocés Gatling, acá te dejo una guía completa y en español). Esto es algo que teníamos pendiente investigar en Abstracta hace tiempo, y finalmente Juan Pablo Sobral pudo terminar esta investigación y bajarlo a este post para compartirlo con todos.
Vale aclarar que en el post te contamos el paso a paso y cada una de las cosas que fuimos encontrando y ajustando en el camino. Al final en la última sección hay un resumen por si querés ir derecho al grano 

Un escenario que nos vamos a encontrar bastante haciendo este tipo de pruebas, es que una sola generadora de carga no es capaz de generar la cantidad de tráfico que deseamos. Otro caso en el que es común distribuir la carga de una ejecución en distintas generadoras es cuando necesitamos simular usuarios desde distintas localizaciones geográficas para mayor realismo del escenario.
En estos casos lo ideal es que la herramienta que estemos utilizando nos provea alguna forma nativa de llevar a cabo esta distribución (como lo hace JMeter por ejemplo).
El objetivo de este post es ayudar a quien esté usando Gatling y necesite realizar ejecuciones distribuidas.
Una de las limitantes de Gatling es que no provee ninguna funcionalidad nativa a la hora de distribuir la carga en distintas generadoras, aunque sí nos provee el script del cual vamos a partir para alcanzar ese objetivo.
Al habernos encontrado con ciertos problemas a la hora de utilizar el script, decidimos armar este post de manera de allanar el camino al que lo vaya a intentar usar.
Pasos a seguir para distribuir carga con Gatling
Esta guía se llevó a cabo utilizando un maestro Ubuntu 19.04 y un esclavo Ubuntu 18.04. O sea, vamos a distribuir la carga entre dos máquinas.
El script que utilizamos para realizar la distribución es el que podemos encontrar en este link (scaling out).
Pre-requisitos
- JDK8+ (esclavos y maestro)
- Instalación portable Gatling (esclavos y maestro)
- Acceso vía clave a los esclavos por ssh
- Cambio de permisos para la carpeta de Gatling en los esclavos y el maestro (nosotros nos decantamos por un chmod 777 para evitar mayor complejidad)
Simulación
Aquí copio la simulación que utilizamos para llevar a cabo este proceso. Te recomiendo usarla en caso de que te cruces un problema no contemplado en este post, para descartar que el problema se encuentre en la simulación que estés usando.
package test
import scala.concurrent.duration._
import io.gatling.core.Predef._
import io.gatling.http.Predef._
import io.gatling.jdbc.Predef._
class LibraryAPI extends Simulation {
val httpProtocol = http
.baseUrl("http://openlibrary.org")
.inferHtmlResources()
.acceptHeader("*/*")
.acceptEncodingHeader("gzip, deflate")
.userAgentHeader("PostmanRuntime/7.24.0")
val feeder = Array(
Map("bookName"->"the lord of the rings"),
Map("bookName"->"fear and loathing in las vegas"),
Map("bookName"->"the catcher in the rye"),
Map("bookName"->"the shining")
).random
object BookSearch {
val getBook = exec (http("Paso 1 - Buscar libro")
.get("/search.json")
.queryParam("title", "${bookName}")
.check(jsonPath("$..author_name[0]").ofType[String].saveAs("authorName"))
)
.pause(1)
}
object AuthorSearch {
val getAuthor = exec(http("Paso 2 - Buscar autor")
.get("/search.json?author=${authorName}")
.check(jsonPath("$..cover_i").find(0).saveAs("coverID"))
)
.pause(1)
}
object CoverSearch {
val getCover = exec(http("Paso 3 - Buscar Tapa del libro")
.get("http://covers.openlibrary.org/b/ID/${coverID}-L.jpg")
.headers(headers_2)
)
}
val scn = scenario("LibraryAPI")
.feed(feeder)
.exec(BookSearch.getBook,
AuthorSearch.getAuthor,
CoverSearch.getCover)
setUp(scn.inject(atOnceUsers(4))).protocols(httpProtocol)
}
Ajustes pre ejecución al script
Antes de lanzar nuestra primera ejecución vamos a ajustar algunos aspectos del script.
Lo primero que tenemos que configurar el nombre de usuario bajo el cual vamos a ejecutar en nuestros esclavos y las IPs de los mismos.
A nosotros nos quedó de la siguiente manera:
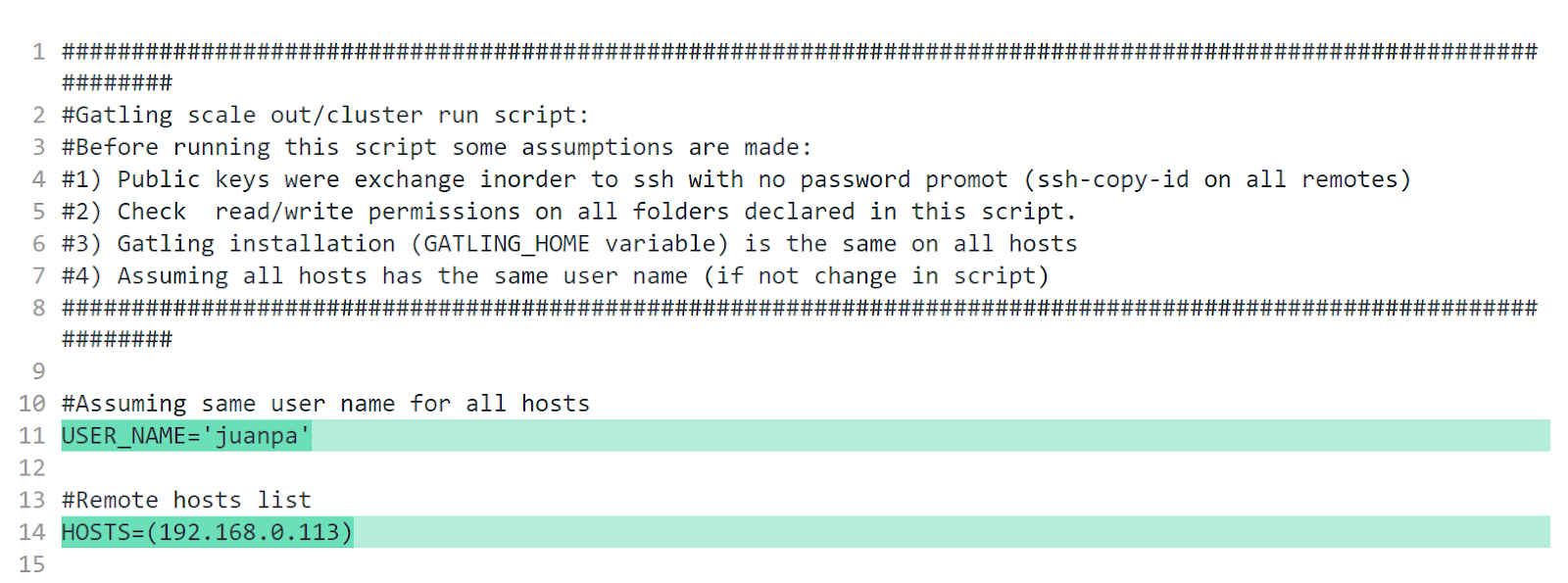
Luego vamos a ajustar los valores de GATLING_HOME, GATLING_SIMULATIONS_DIR, SIMULATION_NAME y (aunque diga que no es necesario cambiarlo) GATHER_REPORTS_DIR.
A nosotros nos quedó de la siguiente manera:
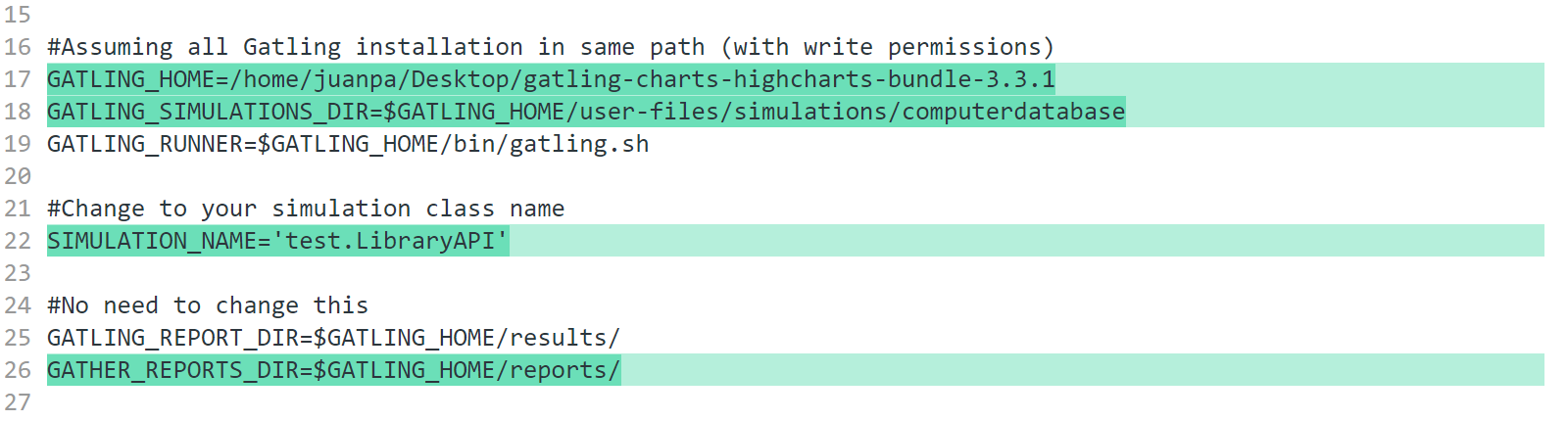
Ajustes necesarios para la ejecución
Luego de estos ajustes, intentamos ejecutar el script pero daba un error al intentar de crear un log para la ejecución en el esclavo, dado que un directorio que el script pretendía usar no existía:

El snippet responsable de esta funcionalidad en el script es el siguiente:

Como podemos ver, el problema ocurre porque intenta crear el log en un directorio que no existe en el esclavo. Para resolverlo, nosotros decidimos almacenar este log dentro del directorio results, dejando el script de la siguiente manera:

También hubo un error al listar los contenidos del directorio results, y al recuperar el archivo que almacenaba los resultados de la ejecución en el esclavo:

Al revisar al esclavo, es evidente que luego del borrado a la carpeta results que se lleva a cabo aquí:

No se vuelve a crear, por lo cual vamos a crear la carpeta a mano y cambiar ese paso para que solo borre los contenidos de la misma, quedando de la siguiente manera:

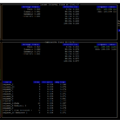
Volvimos a ejecutar el script, y el resultado fue el siguiente:

Esta vez no hubo problemas al generar el log de la ejecución, pero sí los hubo al unir los resultados de las ejecuciones:

Al revisar el esclavo, lo que descubrimos es lo siguiente:

El log de ejecución al estilo salida por consola al que estamos acostumbrados usando Gatling es el archivo report que aparece dentro de la carpeta results, y el reporte que busca el script para unificarlo con el del maestro y elaborar el reporte final, es el simulation.log que se encuentra dentro de la carpeta con el nombre de la simulación y la fecha de ejecución.
Para arreglar el último problema que encontramos, lo que hicimos fue cambiar en esta sección:

La ruta de la cual buscar el resultado de la simulación, de manera que refleje la realidad. Nos quedó así:

Y cuando lo ejecutamos el resultado es el siguiente:

¡Quedó andando!
Pero aún hay un problema…
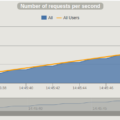
Por cómo está armado nuestro escenario, se deberían generar aproximadamente 120 requests en cada nodo, pero el reporte final en lugar de 240 que esperábamos (120 por cada nodo) reporta menos de 200.
Si chequeamos la salida de consola de la ejecución en ambos nodos podemos ver que se ejecutan 120 request en cada uno, por lo cual el reporte final debería reflejarlo. Pero hay un detalle, el reporte final no se realiza en base a la salida de consola, si no a un archivo que genera Gatling (simulation.log). Si revisamos ese archivo en nuestro esclavo veremos que no contiene todas las request.
Esto ocurre porque toda la ejecución está controlada en base a los tiempos del maestro. Es decir, si cuando el maestro termina el esclavo no llegó aún a generar la totalidad de ese archivo, el maestro no tiene forma de enterarse, e igual se trae los resultados que consigue y los procesa.
Probamos agregar un paso que frene durante treinta segundos el script luego de que finalice la ejecución del escenario en el maestro y parece haber solucionado el problema. Obviamente, este tiempo puede variar según la cantidad de esclavos, los recursos de los cuales disponen y la prueba ejecutada, por lo cual sugiero que primero pruebes sin frenar el script, ver si el reporte final refleja los resultados reales y en caso que falten requests, agregues la pausa en intervalos de 30 segundos hasta alcanzar el tiempo que funcione en tu caso.
Los problemas que tiene el script son principalmente de rutas, que espera que tengan cierta estructura en nuestros entornos y cuando utilizamos una distinta (en este caso puntual, no tengo un directorio gatling incluyendo las distintas versiones portables, en el cual almacenar luego los reportes) puede llegar a generar problemas, pero ninguno demasiado difícil de solucionar como se pudo ver.
A continuación dejamos la versión final del script (la utilizada para realizar este post, reflejando los cambios que se le fueron realizando).
#!/bin/bash
##################################################################################################################
#Gatling scale out/cluster run script:
#Before running this script some assumptions are made:
#1) Public keys were exchange in order to ssh with no password promote (ssh-copy-id on all remotes)
#2) Check read/write permissions on all folders declared in this script.
#3) Gatling installation (GATLING_HOME variable) is the same on all hosts
#4) Assuming all hosts has the same user name (if not change in script)
##################################################################################################################
#Assuming same user name for all hosts
USER_NAME='juanpa'
#Remote hosts list
HOSTS=(192.168.0.113)
#Assuming all Gatling installation in same path (with write permissions)
GATLING_HOME=/home/juanpa/Desktop/gatling-charts-highcharts-bundle-3.3.1
GATLING_SIMULATIONS_DIR=$GATLING_HOME/user-files/simulations/computerdatabase
GATLING_RUNNER=$GATLING_HOME/bin/gatling.sh
#Change to your simulation class name
SIMULATION_NAME='test.LibraryAPI'
#No need to change this
GATLING_REPORT_DIR=$GATLING_HOME/results/
GATHER_REPORTS_DIR=$GATLING_HOME/reports/
echo "Starting Gatling cluster run for simulation: $SIMULATION_NAME"
echo "Cleaning previous runs from localhost"
rm -rf $GATHER_REPORTS_DIR
mkdir $GATHER_REPORTS_DIR
rm -rf $GATLING_REPORT_DIR
for HOST in "${HOSTS[@]}"
do
echo "Cleaning previous runs from host: $HOST"
ssh -n -f $USER_NAME@$HOST "sh -c 'rm -rf $GATLING_REPORT_DIR/*'"
done
for HOST in "${HOSTS[@]}"
do
echo "Copying simulations to host: $HOST"
scp -r $GATLING_SIMULATIONS_DIR/* $USER_NAME@$HOST:$GATLING_SIMULATIONS_DIR
done
for HOST in "${HOSTS[@]}"
do
echo "Running simulation on host: $HOST"
ssh -n -f $USER_NAME@$HOST "sh -c 'nohup $GATLING_RUNNER -nr -s $SIMULATION_NAME > $GATLING_REPORT_DIR/run.log 2>&1 &'"
done
echo "Running simulation on localhost"
$GATLING_RUNNER -nr -s $SIMULATION_NAME
echo "Gathering result file from localhost"
ls -t $GATLING_REPORT_DIR | head -n 1 | xargs -I {} mv ${GATLING_REPORT_DIR}{} ${GATLING_REPORT_DIR}report
cp ${GATLING_REPORT_DIR}report/simulation.log $GATHER_REPORTS_DIR
echo "Waiting for results to be processed in slaves"
sleep 30
for HOST in "${HOSTS[@]}"
do
echo "Gathering result file from host: $HOST"
ssh -n -f $USER_NAME@$HOST "sh -c 'ls -t $GATLING_REPORT_DIR | head -n 1 | xargs -I {} mv ${GATLING_REPORT_DIR}{} ${GATLING_REPORT_DIR}report'"
scp $USER_NAME@$HOST:${GATLING_REPORT_DIR}/*/simulation.log ${GATHER_REPORTS_DIR}simulation-$HOST.log
done
mv $GATHER_REPORTS_DIR $GATLING_REPORT_DIR
echo "Aggregating simulations"
$GATLING_RUNNER -ro reports
Casos borde
Luego de mirar el script, nos pareció que había un par de fallas potenciales. La principal duda que nos surgió era qué pasa si se corta la ejecución por algún motivo en alguno de los esclavos o el maestro.
Obviamente, esto invalida los resultados de la prueba que estamos realizando, pero además puede tener un costo importante de tiempo. Nuestra teoría es que el script no se daría cuenta, y efectivamente así lo comprobamos.
Para sacarnos esta duda, llevamos a cabo varias pruebas para ver cómo se comportaba el script en los distintos escenarios posibles y en base a eso ser conscientes de los potenciales problemas que nos podemos llegar a encontrar al llevar a cabo ejecuciones distribuidas utilizando este script. Dejamos los resultados a continuación.
Matando el proceso en el esclavo:
Dentro de esta prueba, tuvimos en cuenta dos escenarios.
El primero es que la prueba se caiga apenas comienza a ejecutar en el esclavo. En ese caso, lo que ocurrió fue que el script no encontró el archivo de resultados en el mismo y levantó un error. En el caso de nuestra prueba no tiene un gran costo asociado dado que corre en menos de cinco minutos, pero en el caso de que la prueba estuviera ejecutando durante varias horas, habría que conseguir ventanas de tiempo en las que realizar la prueba nuevamente, causando retrasos en los tiempos de entrega.
El segundo es que la prueba se caiga una vez iniciada la ejecución y realizadas algunas request. En este caso, el script no tuvo problema para poder realizar el reporte final, lo cual puede ser considerado aún más peligroso. Si no prestamos demasiada atención, o el número de requests totales del reporte es muy grande, podemos llegar a pasar por alto el hecho de que en alguno de los esclavos se haya cortado el proceso en algún momento, habiendo generado menos carga. En nuestro caso es evidente, dado que esperamos 120 requests por cada uno de los nodos, si en el reporte final aparecen 150 se ve que faltaron algunos. En cambio, si se tratara de una prueba en la que estemos esperando 151.000 y llegan 149.700, la diferencia es menos significativa quizá y la podemos llegar a atribuir erróneamente a algún otro factor.
Matando el proceso en el maestro:
Lo que ocurre al matar el proceso en el maestro es similar a lo que ocurre si matamos el proceso en un esclavo a la mitad de la ejecución. No se levanta ningún error, el script no nos indica en ningún momento que esté ocurriendo nada raro, se traen los resultados parciales de los esclavos y se arma el reporte. Esto también podría ocasionar problemas y además invalida completamente la prueba realizada.
Otros recursos
En nuestra investigación nos cruzamos con esta guía que está muy completa y centraliza gran cantidad de conceptos útiles, por lo cual la recomendamos como complemento para cualquiera que esté iniciándose en el mundo de Gatling.
TL;DR
Para ejecutar Gatling de manera distribuida vamos a tener que realizar algunas modificaciones en el script provisto por la herramienta según explican en la guía Scaling out.
- Primero que nada vamos a tener que modificar las rutas a nuestra instalación de Gatling, el directorio de reportes y resultados.
- También vamos a tener que ajustar el nombre de usuario y las IP para que se correspondan con las que vamos a usar.
- Además, nuestros esclavos y maestro van a tener que cumplir con los prerequisitos (acceso maestro -> esclavo via ssh usando clave, jdk8+ en todos los nodos, cambio de permisos en el directorio de Gatling en todos los nodos).
- Una vez hecho esto, vamos a tener que realizar ajustes sobre el directorio de borrado de resultados previos (borrar los contenidos de la carpeta results, no la carpeta results en si), el archivo al cual se escribe la salida de la ejecución y la ruta de la cual se van a levantar los resultados para armar el reporte.
Todos estos ajustes se pueden encontrar en mayor detalle en la sección Pasos a seguir, incluyendo una simulación de ejemplo que usamos para probar y el script que finalmente nos funcionó.
Gatling es una de las herramientas open source para pruebas de performance que más nos gusta y el haber podido desbloquear esta limitante nos abre otro abanico de posibilidades para su uso. Si necesitás ayuda para distribuir carga con Gatling contactate.